Program Creation for DOS
In this page I depart from electronics proper to explain how programs are made and run in DOS, which is an excellent example of how programs are made and run in any computer system. The complexity of the process to be described is small compared to the great puzzle of putting together a Windows program, but presents all the basic elements of how programs are produced and run. However, it is a very useful process indeed, especially for computer control of electronic devices, so little apology is required for considering it.
It is best to consider a concrete example to make the principles clear, so I shall describe definite procedures and give actual examples. I would like to explain how a program begins as an idea, and becomes a running program on a computer system. I will consider the DOS operating system, and any version from 2.0 up will do. I use PC-Write as an editor; this program is described in another page. Any text editor will do. My assembler is TASM 3.0, an excellent package with all you need to make programs. The linker is TLINK, part of the TASM package. The familiar MASM and MS-LINK will do as well, but may not behave exactly as the Borland programs.
Using DEBUG to make programs has been described in another page. It is easy to make small programs this way, and it is an excellent learning and investigative tool, but rather inconvenient for programs of any size. If you are not very familiar with the 8086 and its descendants, it would be helpful to study DEBUG first.
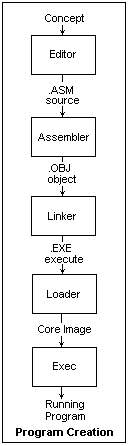 The process of making a program is shown in the diagram at the right. The first step is to type in the program in assembly language into a text editor (EDLIN, PC-Write) and produce the .ASM file, a text file consisting of lines separated by CR LF, and no funny bytes. This file is fed to an assembler, such as TASM, which produces an .OBJ file. This is not a text file, but a binary file, and can only be examined in DEBUG. It contains the assembled bytes and the data that has been declared, but also information on the named symbols and the addresses corresponding to them. It is a rather complicated file, and has to be made with the linker used in mind. The linker, such as TLINK, reads the .OBJ file and massages it into the execute or .EXE file, where all the connections are made between symbols in different .OBJ files. We shall consider only one .OBJ file that calls no library functions, so there are no symbols to fix up, and no other files to be consulted. Nevertheless, in most programs different .OBJ files and library files must all be made to work together. All the code and data is pulled together into a load module, and combined with a header, to make the .EXE file, which is also a binary file. If you wish to investigate it in DEBUG, you must rename it changing the file extension, or DEBUG will load it too, which changes things.
The process of making a program is shown in the diagram at the right. The first step is to type in the program in assembly language into a text editor (EDLIN, PC-Write) and produce the .ASM file, a text file consisting of lines separated by CR LF, and no funny bytes. This file is fed to an assembler, such as TASM, which produces an .OBJ file. This is not a text file, but a binary file, and can only be examined in DEBUG. It contains the assembled bytes and the data that has been declared, but also information on the named symbols and the addresses corresponding to them. It is a rather complicated file, and has to be made with the linker used in mind. The linker, such as TLINK, reads the .OBJ file and massages it into the execute or .EXE file, where all the connections are made between symbols in different .OBJ files. We shall consider only one .OBJ file that calls no library functions, so there are no symbols to fix up, and no other files to be consulted. Nevertheless, in most programs different .OBJ files and library files must all be made to work together. All the code and data is pulled together into a load module, and combined with a header, to make the .EXE file, which is also a binary file. If you wish to investigate it in DEBUG, you must rename it changing the file extension, or DEBUG will load it too, which changes things.
The DOS program EDLIN.EXE mentioned above is a secret weapon. It is a line-based text editor only a little more than 12 KB in size (smaller than one Word .doc file!). It's very inconvenient for writing letters and such, but is good for certain types of editing we often need around a computer. It is not furnished with Windows, but can be found with any version of DOS in the directory holding the external commands. In DOS 5.0 there is even a shell, EDIT.COM, that turns it into a page editor. It's best for files that are naturally organized into lines, such as AUTOEXEC.BAT, assembly source files, and poetry. If you can find EDLIN, it will come in handy. More information is given in an Appendix that will help if you cannot find a manual.
The .EXE file is read by DOS when you type the name of the file after the DOS prompt, and passed to its loader, which is part of DOS. The .EXE file must be made in a format that the loader understands. Later, we will look at this format explicitly. The result of loading is the core image of the program, its actual bytes, which are executable by the processor. The name comes from the historical process, where the program was in magnetic core memory. Finally, DOS calls EXEC to execute the core image, and you have a running program. The operations of the loader and EXEC are invisible to the user.
A program refers to data at certain addresses, and makes jumps and subroutine calls to certain addresses. In the core image, these addresses are actual numbers that do not change. For an embedded system, this presents no difficulty, since the system runs only one program, and it can be made to occupy certain fixed addresses. With DOS and a general-purpose computer, things are very different. The memory (RAM) that holds programs may be very large, perhaps hundreds of megabytes, and the program must be loadable anywhere in this range. There may even be more than one program loaded at a time (DOS can do this, like Windows, but the facilities are not sufficiently developed for general multitasking). This means that some number unknown until load time must be added to all the addresses in the program, a process called relocation.
The 8086 gave an elegant solution to the relocation problem with its segmented address architecture. As you know, an 8086 address consists of two parts, a segment and an offset. To get the physical address, the segment is multiplied by 16 and added to the offset. There are two beauties to this: first, only 16-bit quantities have to be handled; and second, a whole basket of relocation can be done by changing the segment only. Relocation is handled in modern high-capacity machines by hardware address arithmetic, but is equivalent to the segment-offset method.
We recall that the 8086 has four segment registers, DS the data segment, ES as a second data segment, CS the code segment, and SS the stack segment. Each is used by certain instructions. The offset in the code segment is the IP, instruction pointer, while the offset in the stack segment is SP, the stack pointer. How these segments are managed is called the memory model of the program. We have seen in another place that .COM files set all the segment registers to the same value, and work only with offsets. A .COM program is not restricted to this, since it can set the segment registers any way it wants after it begins execution, but normally we use the model for small programs that fit in a 64 KB segment, where it is just like we have no segments at all. The shining advantage of the 8086 is that a .COM program can be loaded anywhere in memory, and the loader only has to set the segment registers to suit. If you have ever relocated an embedded program by a few bytes, you will appreciate what a savings this is. This model is called tiny, but the program does not have to be tiny.
The next step is the use of separate data and code segments. In the assembler, .CODE and .DATA statements can be used to make the assembler assemble bytes in one segment or the other, so that we get two families of offsets, one for code and the other for data, relative respectively to CS and DS. This is sufficiently general to explain how the general process works. This is called the small memory model. Only the desired size of the stack is declared, in a statement like .STACK 200h to create a 512-byte stack. When we do this, there are three segment registers to be initialized by the loader--CS, DS and SS--and two offsets, IP and SP to point to the first instruction in the code segment, and to the top of the stack.
The linker takes the bytes of the code segment, and puts the bytes of the data segment on top of them (at higher addresses). This makes up the load module of the program, that contains all its bytes. It must now tell the loader how to initialize the segment registers, IP and SP. The offsets are easy. IP just points to the entry point of the program, relative to CS, while SP points to the top of the stack, relative to SS (it is simply equal to the stack size in bytes).
The loader first allocates free memory for the program, and sets DS (and ES) equal to the segment at its first byte. The first 100h bytes above this are the Program Segment Prefix, which contains instructions and data for various management purposes. The top of this area is the start segment. Normally, the code segment begins the load module, so CS can be set equal to the start segment. This is just where it is with a .COM program, but now the offsets from CS begin at 0, not 100h. This fixes all the code offsets, which are automatically relocated when CS is. The stack segment SS is usually put at the top of the load module, but more generally can be set any number of paragraphs (16 bytes) above the start segment. It could be higher, for example, if you want some extra data space for creating new variables while the program is running. All that we have left to consider is DS, and it's the most complicated case.
When the program starts, DS points to the PSP, not to a value consistent with the offsets in the data segment of the program. When the program is through with the PSP, it must then set DS properly so its data offsets make sense. This is done with a symbol @data in the assembly, which is shown on the listing file as 0000s, the "s" meaning a segment relocation. The loader is passed the offset of the beginning of the data segment in the load module, and also the offsets in the load module of each "relocation item" or mention of @data. The linker has kindly inserted in each "s" item of the .EXE file the number of paragraphs between the start of the load module and the start of the data segment. All the loader has to do is take CS and add it to the word it finds in the relocation element, then put this in DS. Presto, the data offsets now make sense. Now all the segment registers can be set properly, either by the loader or by the program itself in the case of DS. We will see in detail how this is specified in the .EXE file.
There is one more complication in the case of data. Often the linker likes to combine the data segments of several modules into one big DGROUP. This means that each subsegment has a particular offset from DGROUP. A data address is shown in the listing file as 0200r, or whatever. The "r" means that this address is affected by making a DGROUP. Since we have only one data segment, this will not concern us here, and "r" items will remain unchanged. The linker would have fixed these up when it creates DGROUP in the more general case. The loader leaves them alone.
Now let's look at a concrete example. Consider a program HELLOX which just displays "Hello, World!" on the screen. It's very easy to make a .COM file to do this, but we can also complicate things by putting the code in a .CODE segment and the string in a .DATA segment, using the "small" model. Also, a stack of 200h bytes is declared. 20h bytes of code and 10h bytes of data result, making a load module of 30h bytes. Executing TASM hellox.asm results in the .EXE file hellox.asm. The .OBJ and .EXE files can be examined in DEBUG (changing the filename extension of the latter).
The .EXE fle is 560 bytes long, consisting of a 512-byte header followed by the 30-byte load module. This file is considered as two 512-byte pages long, with the last page containing only 30 bytes. The first few lines of the file are shown below (all the rest in the header are 00).
000: 4D 5A 30 00 02 00 01 00 20 00 20 00 FF FF 03 00
010: 00 02 00 00 11 00 00 00 3E 00 00 00 01 00 FB 50
020: 6A 72 00 00 00 00 00 00 00 00 00 00 00 00 00 00
030: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 12 00
040: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
The first six bytes of the file are 4D 5A 30 00 02 00. The 4D 5A are MZ in ASCII, the initials of the designer of DOS, and are a sign that this is an .EXE file in DOS format. Windows also uses .EXE files, but these two bytes are different, and the DOS loader will not load such files. The .EXE extension means nothing to the loader or the EXEC routing. The next two bytes contain the number of bytes in the last page (30h), and the next two the length of the file in pages (2).
The next eight bytes are 01 00 20 00 20 00 FF FF. The first two are the number of relocation items, 1 in this case, just the one use of the @data symbol used to load DS. The next two are the size of the header in paragraphs, 20h = 32 or 32 x 15 = 512 bytes. The next two, 20 00 or 20h, are the minimum number of paragraphs of memory that are required above the load module. Here they must only accommodate the stack, which is exactly 20h paragraphs long. The FF FF is the maximum number of paragraphs to allocate above the load module, and here the program is being greedy, asking for the maximum amount, which it may or may not get. Anything it gets can be managed by the program--for a huge amount of data, for example.
The next two bytes are 03 00 or 3h, which is the number of paragraphs that the bottom of the stack segment should be above the beginning of the load module. The loader simply adds this to CS to get SS. The next two bytes, 00 02 = 200h, is the intial SP. The next two bytes are 00 00. This should be the negative of the sum of all the bytes of the file, but this checksum is usually ignored, and TLINK does not fill it in. The two following bytes, 11 00 are the initial IP. The two after that, 00 00 as well, are the number of paragraphs CS is from the beginning of the load module, usually zero. The next two, 3E 00, are the offset of the beginning of the relocation table from the start of the header. At offset 3E, indeed, we see 12 00 00 00 as the first (and only) relocation item. In general, the first word is the offset and the second word is the segment from the start of the load module. What the other bytes mean that follow I have no idea, and they have nothing to do with the loading. The bytes in the load module at offset 12h are 02 00, signifying the two paragraphs from the beginning of the CS to the beginning of the DS. All the loader has to do is add the start segment to this, and the core image now contains the proper value of DS to be loaded. That's all there is to it. After you have been through it several times, it will make good sense, and you will realize its generality. The linker can do strange things with the bytes it is given, but the loader can always figure it out.
The load module for this program is shown below. It is the very end of the file. The first two paragraphs are the code, the final one the data: "Hello, World!0." Find the relocation item at offset 12h. The 00 00 a few bytes on is the offset of the string in the data segment. The addresses 200 and so on are those in the .EXE file.
200: B9 00 01 8A 17 43 0A D2 74 06 B4 02 CD 21 E2 F3
210: C3 B8 02 00 8E D8 BB 00 00 E8 E4 FF B4 4C CD 21
220: 48 65 6C 6F 2C 20 77 6F 72 6C 64 21 OD OA 00
It should now be possible to create your own .EXE files for simple programs, which is, in effect, manual linking. There is a huge amount of additional complication for programs with multiple code and data segments (large model) but the principles are exactly the same as have just been described.
.EXE files for high-level languages like C are just the same, and the linker has a lot of work to do, even with the small model. In general, it is simply a matter of linking together modules that are already written, including startup code and termination code, everything coming from libraries that accompany the compiler. The linkers are lazy and just dump in anything, even if only a small part is used (it's easier than figuring out what is needed). These .EXE files tend to be too corpulent for any useful bytewise investigation. A simple "Hello, world!" program with one printf() function makes an .EXE file of 39,235 bytes! There were also 82h relocation elements! There is something wrong here, or at least something that is not pretty.
EDLIN Fundamentals
EDLIN has no built-in Help, and the DOS Help utility does not help, so a DOS manual is the only recourse. The DOS 4.0 manual had a complete discussion of EDLIN, but the program had vanished by DOS 6.22, and is not present in Windows 98. R. A. King, The IBM PC-DOS Handbook, 3rd ed. (Alameda, CA: Sybex, 1988), explained EDLIN, but this and similar books are probably now out of print. This is why EDLIN is a secret weapon. Few people are familiar with line editors today, but they are simple and have advantages.
Let's suppose we want to edit a file "mytext.txt" that may either already exist, or has to be created. Start EDLIN by typing "edlin mytext.txt" at the DOS prompt. EDLIN should either be in the current directory or in the path. Suppose the file already exists. You'll see "End of input file" and an asterisk, EDLIN's prompt, on the next line. You will want to review the file first. Type in "1p" and press Enter. Instead of repeating this in what follows, we'll just say "enter 1p." A screenful of lines is displayed, with the asterisk on the last one. That's the number 1. It would not be necessary to enter the 1 if you were on the first line anyway, but it is usually necessary. Keep entering "p" (Page) until all the file has been displayed, or the line that you want is shown. Every line has a number, and the numbers are automatically adjusted when lines are added or deleted. Only the current line (designated by an *) can be edited. To edit any line, just type in its number and press Enter.
When you are finished editing, entering e (Exit) saves and exits, while q (Quit) exits without saving after asking if you really meant it. You must exit to save, but it is very easy to start again.
Suppose the file is a new one. After starting EDLIN, you will see "New file" and the asterisk on the next line. If you exit with "e" at this time, the new file will be created, but will contain only one byte. A "q" will exit without creating the new file. You cannot edit any lines in the new file, because there are none. Begin insert mode by entering "i" (Insert). Without a number preceding the "i", this command begins inserting lines after the current line. To see what the current line is when you are looking at the *, enter ".". With a number before the i, the new lines are inserted after the line with that number. You'll see "1:*", and now you can type in a line, using backspace to make corrections, or, indeed, any of the DOS line editing commands that use the function keys. When you press Enter, you will see "2:*" and you can enter a second line. Once you have left a line, there is no way to go back without exiting the "i" mode. This is done by the unintuitive Ctrl-Break key combination. Blank lines can be entered simply by pressing Enter. This is the only mode where pressing Enter puts you on the next line. Normally, you just see the * again. The file can be reviewed at any time using "1p" and "p" as explained above, and any line edited by entering its number. When you are editing a line, pressing Esc flushes the line, and you can start over.
Even at this point, you can use EDLIN effectively. There are some more features, however. The lines from n to m can be displayed by "n,mL" (List) without changing the current line (as P does). The lines from n to m can be deleted by "n,mD" (Delete). Upper or lower case letters can be used in the commands, all of which are one letter mnemonics only. To look for a string, for example "psephology," just enter "spsephology", and you will be looking at the first line that contains it. A simple "s" (Search) gets the next occurrence, and so on. This search feature is very easy to use. Don't leave a space between the "s" and the search string, or the space will become part of the search string. The search is case-sensitive. For search and replace, enter "?Rstring1string2" (Replace). This command will search for string1, query you if you want it replaced, and replace it with string2 if you say Y. Without the "?" it would just go ahead and do them all. The is the same as Ctrl-Z, ^Z (hex 1A). A question mark can also be used before the "s" for a similar query about going on. If you want to insert, say, the file nonsense.txt before line n of the file, then enter "nT:nonsense.txt" (Transfer) and it will be done. Lines n through m can be moved to stand before line k with "n,m,kM" (Move), or copied there with "n,m,kC" (Copy). In any command, "." stands for the current line, and "#" for the line after the last line. Instead of specifying the absolute line numbers n,m you can specify them relative to the current line by, say -10 for 10 lines before, or +7 for 7 lines after. To put control characters in a file, use Ctrl-V and then the upper-case letter. That is, Ctrl-V G puts ^G (hex 07) in the file, which will make the printer beep when it is printed. Esc (hex 1B) is ^[.
Two additional commands, A (append) and W (write) are no longer used. They read and wrote lines from and to disk when computer memories were very small, and are hardly needed any more. They do not affect the editing at all. We have now reviewed all the EDLIN commands, which are, to summarize: A, C, D, E, I, L, M, P, Q, R, S, T and W. With a little practice, you will be able to use EDLIN very well.
The DOS editing keys are the following: Ins will insert characters, Del deletes one character, Esc cancels the line, F1 displays one character, F2+char displays the line up to the character specified, F3 displays the whole line, F4+char deletes up to the character specified, and F5 writes the edited line to the buffer. Try these at the DOS prompt to see exactly how they work. They can all be used on the line being edited in EDLIN.
Return to Electronics Index
Composed by J. B. Calvert
Created 20 August 2002
Last revised