A Tale of Two Assemblers
How to define segments and address data
It's really simple: an assembler program eats a text file in assembly language and throws up the resulting bytes. Well, it may be simple in principle, but in fact can be very confusing, because we (or at least I) never seem to have complete information, and features keep growing exponentially. A modern assembler and linker are expected to make 32-bit Windows programs for Pentia as well as .COM files for 8086's, and are required to interface with an assortment of high-level languages, each with its own peculiarities. This page shows how to make simple stand-alone assembly-language programs with two different assembler-linker teams. They really should be considered in pairs, since they must fit together seamlessly. In addition, their target system must also be considered. Here, that is DOS, and by an easy extension, Windows.
The development work was all done on a Pentium III under DOS 6.22, with printing on an HP-540 Deskjet. It is remarkable that this is possible, since the programs will run perfectly on an 8086 from the dawn of the PC era as well. This is neither normal nor casual, but by intelligent design for which we can be very thankful. One set of tools is the Borland Turbo Assembler TASM 4.1 and TLINK 7.0, a relatively recent set from the mid-90's, and the other is Microsoft MASM 1.0, LINK 4.21 and EXE2BIN, from the early-80's Palaeozoic of the PC. The Borland tools take up about 300 KB, while the MS ones scarcely use up 100 KB. This is really not excessive bloat at all, when all the new features are considered.
Of course, you may have different tools and platforms than these, but they will work in a similar manner, and the discussion here can be applied to them. The outstanding difficulty in using assemblers and linkers is the handling of the segmented addresses of the 8086 and descendants, which makes writing programs a little more difficult, but makes relocation very much easier.
For TASM and TLINK, I had pretty good documentation (as good as one usually gets in manuals), but for MASM, LINK and EXE2BIN I had, essentially, none (just recollections). If you type in TASM or TLINK at the DOS prompt without arguments, you get a list of switches that is very useful. MASM and LINK do not have this feature, unfortunately, and their switches and usage are not similar to those of TASM and TLINK. Therefore, a good deal of experimentation was necessary to solve the present problem, which is to find out if the same assembly source file could be assembled and linked with either set of tools. This happens to be possible, which is again a great example of compatibility.
Every assembler will make you a listing file, that shows the source statements and the bytes assembled from it, with error messages if you have committed errors, and certain other information. There is also a list of all the symbols and how the segments are defined and arranged. The listing is typically printed in a compressed font (17 c.p.i.) which will allow a little over 120 characters on a line. I used the DJCP (Deskjet Control Panel) program supplied with the HP-540 to set compressed text, and other modern printers can be controlled the same way. It is difficult to display formatted text in HTML, so you will have to examine your own listing printouts to become familiar with them. The linker makes a similar .MAP file that shows what it did with the segments, but there is not as much useful information. The programs must be instructed to make .LST and .MAP files.
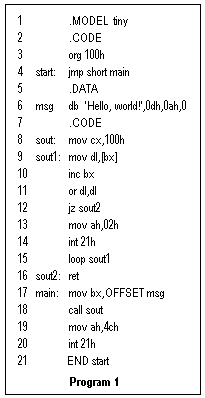 The program should be as short and simple as possible, but with all the essential features. The program I used is a familiar "Hello, world!" program that displays this greeting on the video screen. It is shown at the right as prepared for the TASM assembler, using simplified segment directives. The main routine loads the address of the string, calls a subroutine to display it, then exits with DOS function 4Ch. One can use an ASCII string terminated by "$", but this routine prints out a zero-terminated ASCII string like those used in C. Since there are more zeros in memory than $'s, there is less chance of the program's tediously running away if something goes wrong. There is a counter that allows printing of 256 bytes maximum. There are, therefore, two segments to define, a code segment addressed relative to CS, and a data segment addressed relative to DS. In addition, the program must have a stack.
The program should be as short and simple as possible, but with all the essential features. The program I used is a familiar "Hello, world!" program that displays this greeting on the video screen. It is shown at the right as prepared for the TASM assembler, using simplified segment directives. The main routine loads the address of the string, calls a subroutine to display it, then exits with DOS function 4Ch. One can use an ASCII string terminated by "$", but this routine prints out a zero-terminated ASCII string like those used in C. Since there are more zeros in memory than $'s, there is less chance of the program's tediously running away if something goes wrong. There is a counter that allows printing of 256 bytes maximum. There are, therefore, two segments to define, a code segment addressed relative to CS, and a data segment addressed relative to DS. In addition, the program must have a stack.
My actual program has a few comments, which begin with ";" and extend to the end of the line, but they are omitted in the examples here. If you are writing code that will be used by other people, a comment header can explain what a routine does, what its data is like, how it responds to errors, and what are the entry and exit points. Other comments should only explain the non-obvious, giving reasons and considerations that you may forget at a later time. Many assembler programs are overgrown with comments, which obscure rather than clarify. It is easier to write comments than code, but both look like work, so if one is paid by the line, comments tend to blossom.
It is very easy to produce an .EXE file that will handle the code and data segments separately. The only thing to remember is that when an .EXE file is loaded by DOS, the DS remains set at the PSP, not at the proper value for addressing the data segment, which must be explicitly loaded by the program. How this works is explained on another page, where the structure of an .EXE file is described. How to make a simpler .COM file has also been explained, in connection with DEBUG, which makes it easy for small programs. This COre iMage contains the exact bytes of the program, and can be loaded anywhere, the segment registers performing all the relocation automatically. In this page, I want to see how to make a .COM file with assembly tools.
With TASM, the procedure is this: the program must begin at the first byte of the load module. This can be guaranteed by placing ORG 100h at the beginning of the code segment, and then starting the program there, or placing a jump there to the actual start of the program, as is done in Program 1. The .MODEL directive must specify "tiny", and nothing can be said about any STACK segment. The executable statements are all put in a .CODE segment and the data is all put in a .DATA segment. These directives turn on emission of bytes in the particular segment, and turn off emission in the other. In Program 1 the code segment is opened, then closed as the data segment is opened, and then reopened after the data has been defined. Data is referenced by symbols in the data segment in a normal way. The file is assembled with TASM, then linked with TLINK with a /t switch, and the result is a .COM file, as if by magic. Magic, indeed, because a lot goes on behind the scenes.
When a .COM file is loaded by DOS, it is not checked to be sure that it actually is an executable .COM file. The first free segment is put into all the segment registers, and the load module is loaded at offset 100h. The instruction pointer is set to 0100h, and the stack pointer to FFFEh. This means that execution will begin at CS:100, and that the stack is at the top of the 64 KB segment. DOS also puts two bytes of zeros at the top of the segment, so that if the program does a RET, it goes to CS:0, where there are instructions to return to DOS. All allocatable memory is allocated to the program. A .COM program is small only in the sense that the load module is restricted to 64 KB. Once it gets control, it can do anything with all of the memory, load segment registers at will, and generally behave powerfully.
With MASM, the following must be done: the program is written as before, but there are no MODEL directives, and no simplified segment directives like .CODE and .DATA that do things behind the scenes. The segments must be explicitly named and declared. As before, ORG 100h is used, and no stack segment is mentioned. When the program is linked, LINK objects to the absence of a stack, and says an error has been committed. Nevertheless, it does make an .EXE file anyway, but not one that you can run with any safety. This file must be converted by the EXE2BIN program that rips out the load module and puts it first. DOS will now proceed as explained above, setting all the segment registers to the same thing, and initializing the IP and SP. If the program is not written properly, then this will not work. If EXE2BIN finds a real .EXE program, it cannot convert it, and tells you so. Now rename your program with a .COM extension instead of the .BIN extension. Exactly the same .COM file is obtained as with TASM.
We have to know how the assembler and linker handle segments to solve our problems, and here is the greatest benefit of the exercise. We can assemble and link, then look at the .COM file in DEBUG. A little tracing will then show whether we have addressed the string properly, which is the key to the whole business. It is always better to use DEBUG than to try to run the program directly after linking or EXE2BIN. Just because a program assembled and linked without errors is no sign that it will run properly!
 The program shown at the right begins the program at the first byte in the code segment, so there is no need for a jump. Procedure declarations are also shown. These are optional, but clarify the modularization, and make it easy to specify what kind of call is necessary to access them, NEAR or FAR. A NEAR call is in the same segment, and only the IP is saved and restored. A FAR call changes the code segment register as well. These procedures are both NEAR, of course, in this case.
The program shown at the right begins the program at the first byte in the code segment, so there is no need for a jump. Procedure declarations are also shown. These are optional, but clarify the modularization, and make it easy to specify what kind of call is necessary to access them, NEAR or FAR. A NEAR call is in the same segment, and only the IP is saved and restored. A FAR call changes the code segment register as well. These procedures are both NEAR, of course, in this case.
Now to the magic. We begin a code segment with: _CODE SEGMENT WORD PUBLIC 'CODE'. The name of the segment is _CODE, and this has a numerical value equal to the segment value (which is unknown at this stage). We can choose any name we like; there is nothing special about _CODE. SEGMENT is the notice to the assembler that we are opening a segment. WORD means that the segment should begin on an even address. Other possibilities are BYTE and PARA. A PARA, paragraph, is 16 bytes (unity in the lowest digit of a segment). PUBLIC means that when another segment with the same name is opened, it will just be concatenated to this one (and eventually accessed with the same segment value). The alternative is PRIVATE. Finally, 'CODE' is a class of segments. In this case, it might identify other code segments not named _CODE and throw them in with this one. CODE is just an arbitrary name, nothing special. That is, we could write TORP SEGMENT WORD PUBLIC 'RUBBISH' and put code in it all the same.
To end this segment, _CODE ENDS (or TORP ENDS) is used. MASM demands the name, TASM can take it or leave it. Now we can open _DATA SEGMENT WORD PUBLIC 'DATA' in the same way, and end it with _DATA ENDS. If we had a stack, we would need STACK SEGMENT PARA STACK 'STACK' and STACK ENDS. The word STACK might just have some meaning to the linker, since stack segments are handled a bit differently than other segments. As far as the other segments are concerned, we could put data in _CODE and code in _DATA, but this would just be perverse.
Now something quite confusing is necessary, though it is really simple at heart. Since we are going to refer to all our segments with one segment value in the final program, we must create a group with DGROUP _CODE,_DATA. This means that _DATA and _CODE will be concatenated, and everything in them can be accessed by the offset relative to a segment value DGROUP. The linker will stack up the segments in the order they were encountered, in general. In MASM, they are put in alphabetical order (select names accordingly). This is simple, but has led to oceans of confusion. In the data segment, we use the symbol szMsg to mark the start of the output string. With the simplified directives of TASM, we could just say szMsg and all would be right. After making the group, we must say DGROUP:szMsg instead. If we just used szMsg, we would get the offset of szMsg in _DATA, which is not the same as the offset in DGROUP (the whole code segment intervenes). I must have tried twenty ways to address the data properly, but this is the only one that worked. It is also necessary for the code segment to be first (lowest) in DGROUP so that the entry point is correct, so it is named first in the GROUP directive.
Line 4 shows the ASSUME directive. This directive actually does nothing except helping the assembler detect improper segment usage in the source code, telling it if symbols used belong to the proper segment. It definitely does not check that the proper segment value is actually in the segment register. There is even ASSUME NOTHING or ASSUME DS:NOTHING that eliminates any association of a segment name and a segment register. Nothing has to be assumed in a data segment. The ASSUME should be changed when you change a segment register. The ASSUME CS:_CODE,DS:_DATA or CS:DGROUP,DS:DGROUP, in this case, is essential and should be declared at the beginning of the code segment, or the assembler will object at every procedure call and every data access.
Now we have a source assembly file that will be accepted by both MASM and TASM, a wonderful thing indeeed. In both cases we wind up with a file 44 bytes long that says "Hello, world!" when we type the program name at the DOS prompt. Incidentally, the EXE2BIN conversion process vanished somewhere between MASM 1.0 and MASM 5.2. It is something that the linker could do very easily, as indeed it does in the Borland tools.
To be able to link a routine with a high-level language, you have to put the code and data in the proper segments, which means knowing how the language declares its segments and groups. For example, Borland code segments are named _TEXT. Shared identifiers must be made PUBLIC where they are defined, and EXTRN where they are used but not defined. These identifiers appear in the .OBJ files produced by assemblers and compilers, and the linker matches them up. It is much easier within one language family, such as Borland's, because the naming will be consistent, and simplifications are available. This makes it easier to interface modules produced by TASM with Borland C++, but when you go to an arbitrary host language, the Borland simplifications will not work at all, and you will be helpless. In general, if you can compile a high-level program to assembly language, the segment declarations and other details will be clear, so you can copy them into your routine. Once all this paperwork is done, the process is actually easy.
A stand-alone assembly program consists of assembly modules only. One has complete control over naming and declarations, which makes everything very much easier. It is easy to make a multi-module program using the linker. The order of .OBJ files submitted to the linker is immaterial, and the linker will figure out all the PUBLIC-EXTRN correspondences. When using libraries, however, the order of linking may be very important. If you have an assembly library, it should usually be linked in last. Libraries must be put together with a librarian program that knows what the linker likes, such as TLIB for TLINK.
Return to Electronics Index
Composed by J. B. Calvert
Created 22 August 2002
Last revised